Today let’s try to understand what is Numa and how it helps?
Numa full name is Non-Uniform Memory Architecture. To understand this, let’s first understand the basic OS working.
Whenever a process “P1” has to execute its instructions it has to get the CPU allocation. The process starts from a hard disk where your main program is saved. As we know main memory RAM is expensive and limited in capacity there is a limitation that not all the programs can be run which is stored in the Hard disk although it tries to load as much as it can.
The process once loaded in the main memory then starts executing and If a process is interrupted, let’s say it was interrupted for input/output then the CPU takes up another process and puts the existing process in waiting. The more processes it executes the more CPU is utilized and we call this the degree of multiprogramming.
Symmetric Multiprocessing
A process runs the data and its address is loaded in the processor and is travelled from various components of buses(group of wires). To increase the performance you can use the multicore processor. However, when we use more cores the shared system bus which connects the CPU to the main memory gets very busy. As we increase the number of cores the bus will throttle since it is being used heavily by all the processors.

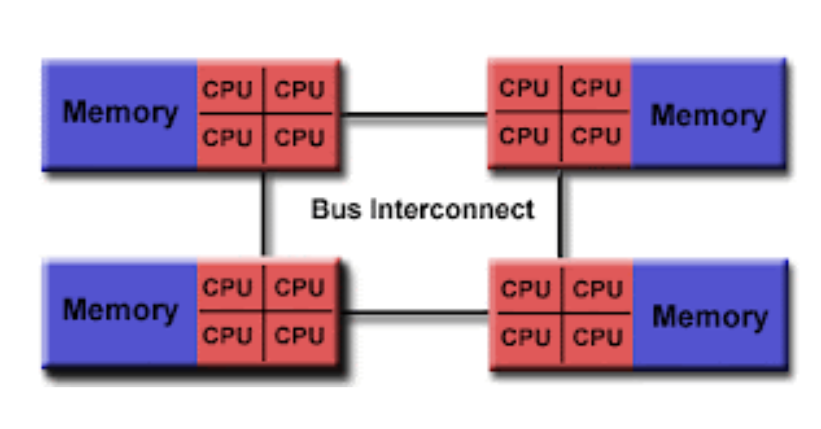
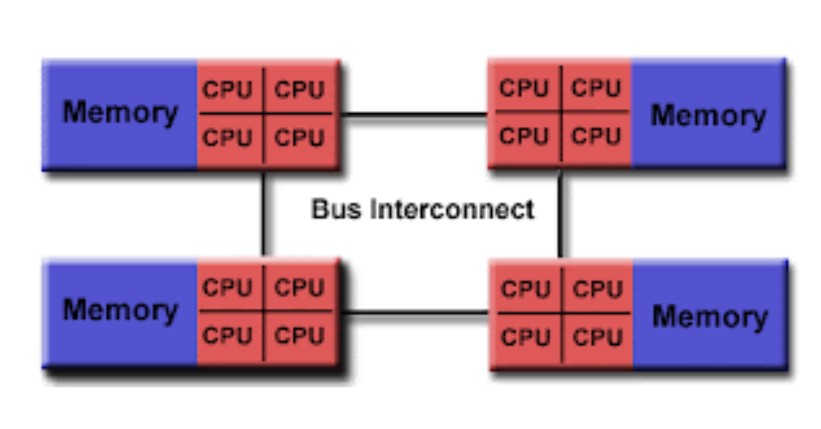
NUMA
To overcome the issue wherein all the data is travelled through a common bus a new hardware trend came in where the separate bus is used by each processor. Non uniform memory Architecture is a new design in the hardware that removes these concerns. In this design, every process has its dedicated memory and its I/O’s. Each of them is divided into the form of groups and each group is known as NUMA NODE. A NUMA node can access the memory of another NUMA node which is also known as remote memory access, however, that takes much time in comparison to Local memory. A node can contain multiple processors and this depends upon the choice of the vendor.
Soft NUMA
Usually, processors have multiple cores within them and the processors are divided by sockets. These sockets are NUMA Nodes. When we use software NUMA we can divide the hardware Nodes which then increases the performance. Starting from SQL 2016, NUMA is by default configured whenever the instance starts, although the condition for this is that the server should be having more than 8 physical cores. Furthermore, whenever the SQL server starts, internally the SQLOS creates the schedulers based on the logical processors. The same information can be viewed with the help of DMV named sys.dm_os_schedulers
select * from sys.dm_os_schedulers where status='visible online'
I ran this on my machine which is having 4 Cores and 8 Logical processors. Point to note is that since executing the process in local memory is much faster than remote memory access, the SQL Server knows this fact and hence it always tries to use the same scheduler and node when it requests for more memory to run all new queries.
Summary
SMP architecture is fine when you’re using less number of processors however when the cores are added then it becomes a bottleneck for the motherboard. The main benefit of NUMA is that it is scalable. Each core in the NUMA node has its own memory node and when it wants to access the data from another memory node then it can easily ask for, however with some latency as compared to local memory.
